7.1. Monitoring
What is AI/ML Monitoring?
AI/ML Monitoring is the continuous process of overseeing the performance, behavior, and health of machine learning models in production environments. It's an essential aspect of MLOps that extends beyond the initial training and deployment stages, ensuring that models remain effective and reliable throughout their operational lifecycle. Effective monitoring involves several key tasks, including:
- Tracking Metrics: Capturing and analyzing key performance indicators (KPIs) that reflect the model's accuracy, precision, recall, and other relevant metrics over time.
- Setting up Alerts: Establishing trigger mechanisms that alert stakeholders when specific conditions are met, such as a significant drop in model accuracy or the detection of data drift.
- Gaining Insights: Providing a means to understand and diagnose issues through visualizations, logs, and other diagnostic tools.
Effective AI/ML monitoring helps prevent model decay, which occurs when model performance deteriorates over time, by quickly identifying issues, enabling timely interventions. It is crucial for both technical teams and business stakeholders to maintain confidence in the accuracy and value of AI/ML solutions.
How does AI/ML Monitoring differ from Traditional Software Monitoring?
While AI/ML monitoring shares similarities with traditional software monitoring, it also presents unique challenges:
- Non-Deterministic Behavior: Machine learning models can exhibit unpredictable behavior due to their reliance on data patterns. These patterns may change over time, leading to performance degradation or unexpected outputs.
- Complex Dependencies: AI/ML applications often depend on multiple external factors, including data sources, feature engineering pipelines, and serving infrastructure. Monitoring must encompass all these dependencies to identify potential sources of issues.
- Black Box Nature: The internal workings of some machine learning models can be opaque, making it harder to directly diagnose the reasons for incorrect predictions or behavior changes.
These unique challenges call for specialized tools and strategies, as traditional monitoring systems may not be adequately equipped to address the complexities inherent in AI/ML applications.
What are the Benefits of AI/ML Monitoring?
- Early Problem Detection: By continuously monitoring metrics and setting up alerts, teams can detect problems such as model drift, data quality issues, or biases before they significantly impact business outcomes.
- Improved Model Performance: Tracking metrics helps identify opportunities for model retraining, hyperparameter tuning, or other optimizations to enhance model performance over time.
- Increased Reliability: Effective monitoring safeguards against model failures and downtime, ensuring that AI/ML solutions remain stable and dependable, maintaining business continuity.
- Enhanced User Trust: By ensuring model accuracy and fairness, monitoring practices build trust and confidence in AI/ML solutions among users, promoting their adoption and use.
AI/ML monitoring plays a crucial role in bridging the gap between model development and production, ensuring that these solutions remain valuable and reliable assets for businesses.
Which Metrics Should You Track for AI/ML Monitoring?
The metrics tracked for AI/ML monitoring should align with the specific objectives and performance requirements of the model:
Common Metrics
- Accuracy, Precision, Recall, F1 Score: These metrics assess the model's overall performance and its ability to correctly classify or predict outcomes.
- Mean Absolute Error (MAE), Mean Squared Error (MSE), Root Mean Squared Error (RMSE): These metrics quantify the magnitude of prediction errors, crucial for regression problems.
- Area Under the Receiver Operating Characteristic Curve (AUC-ROC): This metric evaluates the model's ability to distinguish between different classes, particularly useful for binary classification problems.
Business Metrics
Beyond technical metrics, aligning monitoring with business goals through relevant metrics is crucial:
- Conversion Rate, Customer Churn, Revenue Impact: These metrics measure the direct impact of the model on business outcomes, offering a clear view of its effectiveness.
Data Quality Metrics
- Data Drift, Missing Values, Outliers: Monitoring data quality metrics helps detect changes in input data distribution or format that could impact model performance.
How can you implement AI/ML Monitoring with MLflow?
The MLOps Python Package utilizes Mlflow's evaluate API for comprehensive model evaluation, including the validation of results with user-defined thresholds. This capability allows for a standardized approach to model monitoring, ensuring that model quality is consistently assessed and monitored.
Here's how you can implement this monitoring functionality:
-
Define Metrics: First, define the metrics you want to track using a class from the
bikes.core.metricsmodule. This class allows you to specify the metric name and whether a higher or lower score indicates better performance.from bikes.core import metrics metrics = [ metrics.SklearnMetric(name="mean_squared_error", greater_is_better=False), metrics.SklearnMetric(name="r2_score", greater_is_better=True), ] -
Set Thresholds (Optional): If you want to establish thresholds for specific metrics, use the
Thresholdclass, again frombikes.core.metrics, to define the absolute threshold value and whether a higher or lower score is desired. These thresholds serve as benchmarks for model performance, potentially triggering alerts if violated.thresholds = { "r2_score": metrics.Threshold(threshold=0.5, greater_is_better=True) } -
Integrate with the
EvaluationsJob: TheEvaluationsJobin thebikes.jobs.evaluationsmodule is responsible for loading the registered model, reading the evaluation dataset, and calculating the specified metrics. You can configure this job to use the defined metrics and thresholds.from bikes import jobs from bikes.io import datasets evaluations_job = jobs.EvaluationsJob( inputs=datasets.ParquetReader(path="data/inputs_test.parquet"), targets=datasets.ParquetReader(path="data/targets_test.parquet"), metrics=metrics, thresholds=thresholds, ) -
Execute the Job: Run the
EvaluationsJobto compute the metrics and assess them against the thresholds. If any thresholds are violated, MLflow will raise aModelValidationFailedException, which can be handled appropriately in your workflow.with evaluations_job as runner: runner.run()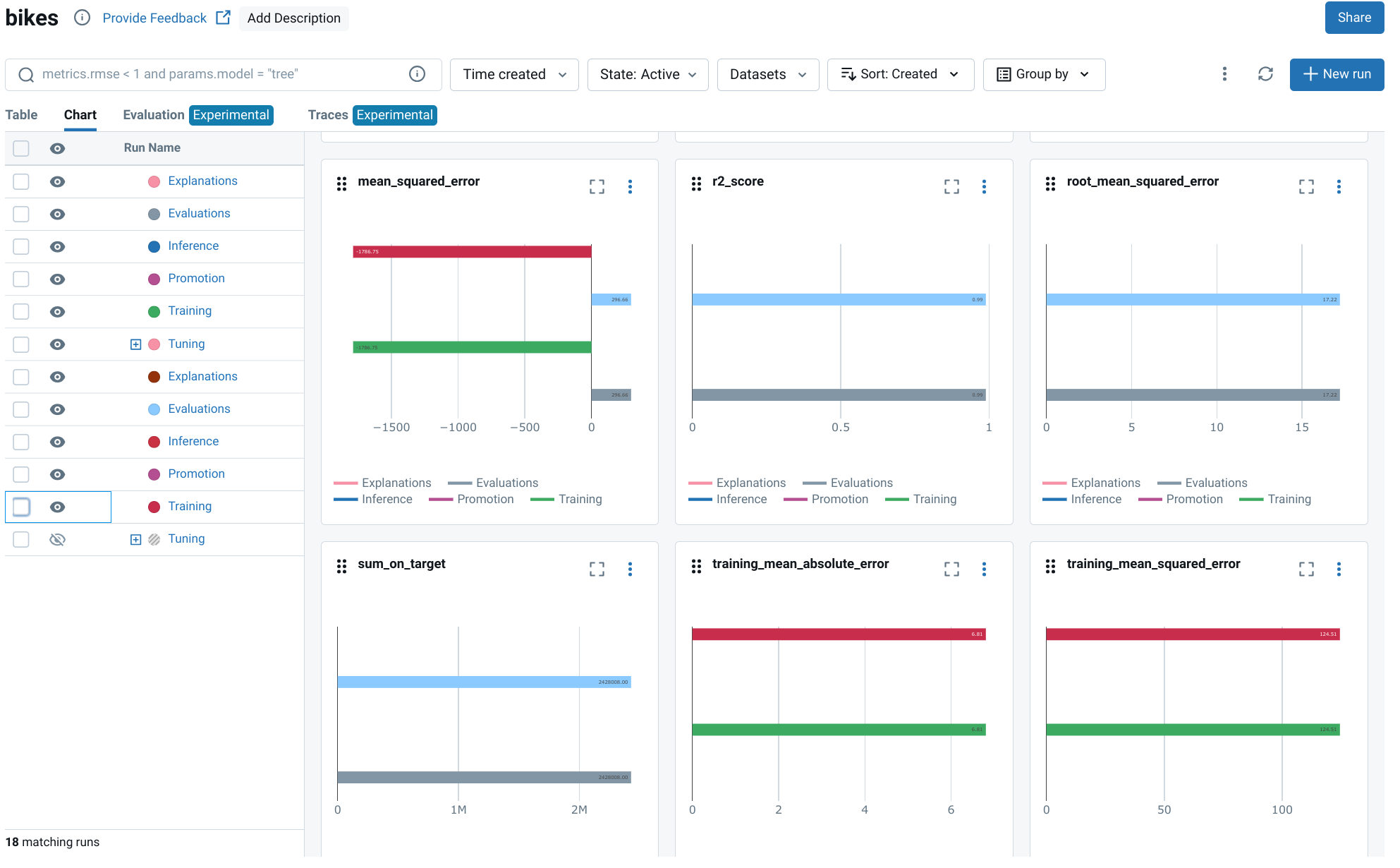
How to integrate AI/ML Monitoring to your data infrastructure?
You can use the Evidently library to generate interactive reports for model monitoring and analysis. Evidently supports data and target drift detection, model performance monitoring, and the creation of visual reports to understand changes and issues within an ML pipeline. It simplifies the tracking and analysis of changes in model behavior, making the monitoring process more efficient and effective.
Here are the steps to integrate Evidently into your Jupyter notebooks for model monitoring:
- Install the Evidently library:
pip install evidently
- Import necessary modules:
import pandas as pd
from evidently.report import Report
from evidently.metric_preset import DataDriftPreset
- Load your reference and current data: These datasets represent the data the model was trained on (reference) and the data the model is currently making predictions on (current).
reference_data = pd.read_csv('reference.csv')
current_data = pd.read_csv('current.csv')
- Generate an Evidently report:
report = Report(metrics=[DataDriftPreset()])
report.run(reference_data=reference_data, current_data=current_data)
report.show() # or report.save_html('my_report.html')
This example will generate a report highlighting any data drift between the reference and current datasets, which can be crucial in identifying why a model's performance might be declining.
What are the Best Practices for AI/ML Monitoring?
- Establish Clear Monitoring Goals: Define the objectives of your monitoring efforts, which might include detecting drift, maintaining performance, or ensuring fairness.
- Choose Relevant Metrics: Select metrics that align with the specific objectives of your model and your business goals.
- Set up Meaningful Alerts: Design alerts that are actionable and relevant, avoid alert fatigue, and ensure timely responses to critical issues.
- Integrate Monitoring into CI/CD Pipelines: Incorporate monitoring steps into your continuous integration and continuous deployment (CI/CD) workflows to ensure that changes are thoroughly evaluated and monitored.
- Visualize Results: Utilize visual dashboards and reports to present monitoring results in an easily understandable format for both technical and business stakeholders.
- Regularly Review and Update: Periodically review your monitoring setup and adjust metrics, thresholds, and alerts as needed based on experience and changing requirements.