3.2. Paradigms
What is a programming paradigm?
A programming paradigm is a fundamental style or approach to writing code. It provides a conceptual framework for how you structure and solve problems, influencing how you organize logic, manage data, and think about program flow.
Key paradigms relevant to MLOps include:
- Procedural Programming: Organizes code as a linear sequence of instructions or procedures (functions) that perform tasks step-by-step. It's direct and often used for simple scripts.
- Object-Oriented Programming (OOP): Models the world using "objects" that bundle data (attributes) and the behaviors that operate on that data (methods). This encapsulation is key for building complex, modular systems.
- Functional Programming (FP): Treats computation as the evaluation of mathematical functions. It emphasizes immutability (non-changing data) and avoids side effects, leading to more predictable and testable code.
- Declarative Programming: Focuses on describing what the program must accomplish, leaving the how to the underlying platform. You declare the desired outcome rather than writing the step-by-step execution logic.
Can you provide code examples for MLOps with each paradigm?
Procedural Programming
The procedural approach executes a sequence of steps in a single, linear script. It is common in initial data analysis and notebook-based experiments due to its simplicity and directness. While effective for simple tasks, this paradigm becomes difficult to maintain, test, and scale as project complexity grows.
# Simplistic AI/ML Python Script Example
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# Load and preprocess data
data = pd.read_csv('dataset.csv')
data.fillna(0, inplace=True)
# Split data
X, y = data.drop('target', axis=1), data['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train model
model = LogisticRegression()
model.fit(X_train, y_train)
# Evaluate model
predictions = model.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
print(f"Model Accuracy: {accuracy}")
Functional Programming
Functional programming structures code into a series of independent, reusable functions. This paradigm emphasizes immutability and the avoidance of side effects, making each function a predictable and testable unit. In MLOps, this is ideal for data transformation pipelines, where a series of pure functions can be composed to process data without unexpected changes to the state.
The example below uses functions for each step of the workflow and a higher-order function (get_model) to select a model dynamically.
from typing import Callable, Tuple
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.base import BaseEstimator
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
def load_and_preprocess_data(filepath: str, fill_na_value: float, target_name: str) -> Tuple[pd.DataFrame, pd.Series]:
"""Load and preprocess data."""
data = pd.read_csv(filepath)
data = data.fillna(fill_na_value)
X = data.drop(target_name, axis=1)
y = data[target_name]
return X, y
def split_data(X: pd.DataFrame, y: pd.Series, test_size: float, random_state: int) -> Tuple[pd.DataFrame, pd.DataFrame, pd.Series, pd.Series]:
"""Split the data into a train and testing sets."""
return train_test_split(X, y, test_size=test_size, random_state=random_state)
def train_model(X_train: pd.DataFrame, y_train: pd.Series, model_func: Callable[[], BaseEstimator], **kwargs) -> BaseEstimator:
"""Train the model with inputs and target data."""
model = model_func(**kwargs)
model.fit(X_train, y_train)
return model
def evaluate_model(model: BaseEstimator, X_test: pd.DataFrame, y_test: pd.Series) -> float:
"""Evaluate the model with a single metric."""
predictions = model.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
return accuracy
def get_model(model_name: str) -> Callable[[], BaseEstimator]:
"""High-order function to select the model to train."""
if model_name == "logistic_regression":
return LogisticRegression
elif model_name == "random_forest":
return RandomForestClassifier
else:
raise ValueError(f"Model {model_name} is not supported.")
def run_workflow(model_name: str, model_kwargs: dict, filepath: str, fill_na_value: float, target_name: str, test_size: float, random_state: int) -> None:
"""Orchestrate the training workflow."""
X, y = load_and_preprocess_data(filepath, fill_na_value, target_name)
X_train, X_test, y_train, y_test = split_data(X, y, test_size, random_state)
model_func = get_model(model_name)
model = train_model(X_train, y_train, model_func, **model_kwargs)
evaluate_model(model, X_test, y_test)
# Example usage
run_workflow(
filepath='dataset.csv',
fill_na_value=0.0,
target_name='target',
test_size=0.2,
random_state=42,
model_name='random_forest', # Or 'logistic_regression'
model_kwargs={'n_estimators': 30},
)
Object-Oriented Programming (OOP)
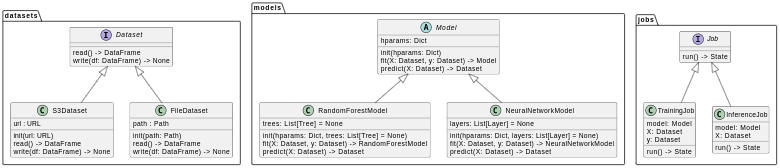
Object-Oriented Programming (OOP) organizes code around objects, which encapsulate both data (attributes) and behavior (methods). This paradigm is exceptionally well-suited for managing the complexity of production MLOps systems. By modeling concepts like datasets, models, and training workflows as objects, you create a modular, extensible, and maintainable codebase.
This example defines an abstract Model base class and concrete implementations for different model types (RandomForestModel, KerasBinaryClassifier). A ModelFactory creates model instances, and a Workflow class orchestrates the entire process.
from abc import ABC, abstractmethod
from typing import Tuple, Type
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.base import BaseEstimator
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
class Model(ABC):
"""Abstract base class for models."""
@abstractmethod
def train(self, X_train: pd.DataFrame, y_train: pd.Series) -> None:
pass
@abstractmethod
def predict(self, X: pd.DataFrame) -> pd.Series:
pass
class RandomForestModel(Model):
"""Random Forest Classifier model."""
def __init__(self, n_estimators: int = 20, max_depth: int = 5) -> None:
self.model = RandomForestClassifier(n_estimators=n_estimators, max_depth=max_depth)
def train(self, X_train: pd.DataFrame, y_train: pd.Series) -> None:
self.model.fit(X_train, y_train)
def predict(self, X: pd.DataFrame) -> pd.Series:
return self.model.predict(X)
class KerasBinaryClassifier(Model):
"""Simple binary classification model using Keras."""
def __init__(self, input_dim: int, epochs: int = 100, batch_size: int = 32) -> None:
self.epochs = epochs
self.batch_size = batch_size
self.model = Sequential([
Dense(64, activation='relu', input_shape=(input_dim,)),
Dense(1, activation='sigmoid')
])
self.model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
def train(self, X_train: pd.DataFrame, y_train: pd.Series) -> None:
self.model.fit(X_train, y_train, epochs=self.epochs, batch_size=self.batch_size)
def predict(self, X: pd.DataFrame) -> pd.Series:
predictions = self.model.predict(X)
return (predictions > 0.5).flatten()
class ModelFactory:
"""Factory to create model instances."""
@staticmethod
def get_model(model_name: str, **kwargs) -> Model:
# Assume all model classes are defined in the global scope.
model_class = globals()[model_name]
return model_class(**kwargs)
class Workflow:
"""Main workflow class for model training and evaluation."""
def run_workflow(self, model_name: str, model_kwargs: dict, filepath: str, fill_na_value: float, target_name: str, test_size: float, random_state: int) -> None:
X, y = self.load_and_preprocess_data(filepath, fill_na_value, target_name)
X_train, X_test, y_train, y_test = self.split_data(X, y, test_size, random_state)
model = ModelFactory.get_model(model_name, **model_kwargs)
model.train(X_train, y_train)
accuracy = self.evaluate_model(model, X_test, y_test)
print(f"Model Accuracy: {accuracy}")
def load_and_preprocess_data(self, filepath: str, fill_na_value: float, target_name: str) -> Tuple[pd.DataFrame, pd.Series]:
"""Load and preprocess data."""
data = pd.read_csv(filepath)
data = data.fillna(fill_na_value)
X = data.drop(target_name, axis=1)
y = data[target_name]
return X, y
def split_data(self, X: pd.DataFrame, y: pd.Series, test_size: float, random_state: int) -> Tuple[pd.DataFrame, pd.DataFrame, pd.Series, pd.Series]:
"""Split the data into a train and testing sets."""
return train_test_split(X, y, test_size=test_size, random_state=random_state)
def evaluate_model(self, model: Model, X_test: pd.DataFrame, y_test: pd.Series) -> float:
"""Evaluate the model with a single metric."""
predictions = model.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
return accuracy
# Example usage
workflow = Workflow()
workflow.run_workflow(
filepath='dataset.csv',
fill_na_value=0.0,
target_name='target',
test_size=0.2,
random_state=42,
model_name='RandomForestModel', # Or 'KerasBinaryClassifier'
model_kwargs={'n_estimators': 30},
)
Declarative Programming
Declarative programming focuses on defining what you want to achieve, not how you want to achieve it. Instead of writing step-by-step instructions, you declare the desired state or outcome, and the underlying framework handles the implementation. This is common in MLOps for defining infrastructure (Terraform, Kubernetes) and configuring complex model pipelines.
For example, Ludwig uses a YAML file to declare a model's architecture and training parameters. You define the components and their settings, and Ludwig builds and trains the model accordingly.
# config.yaml
input_features:
- name: image_path
type: image
encoder:
type: stacked_cnn
conv_layers:
- num_filters: 32
filter_size: 3
pool_size: 2
pool_stride: 2
- num_filters: 64
filter_size: 3
pool_size: 2
pool_stride: 2
dropout: 0.4
fc_layers:
- output_size: 128
dropout: 0.4
output_features:
- name: label
type: category
trainer:
epochs: 5
To train the model using this configuration, you would run the following command:
ludwig train --dataset mnist_dataset.csv --config config.yaml
Why are functions and objects essential in MLOps?
In MLOps, moving from a simple script to a production system requires robust code structure. Functions and objects are the primary tools for achieving this.
-
Functions are used to implement abstraction. They hide complex logic behind a simple interface (the function call), allowing you to reuse code without worrying about the implementation details. This makes your code more modular and easier to test. A function should have a single, clear responsibility.
-
Objects are used for encapsulation. They bundle related data (attributes) and the functions that operate on that data (methods) into a single unit. This is perfect for modeling complex concepts in MLOps, such as a
Datasetthat holds data and methods for loading and transforming it, or aModelTrainerthat encapsulates the logic for training and evaluation.
How do you decide when to create a function or an object?
The decision to create a function or an object depends on whether you need to manage state (data) along with behavior.
- Create a function when you have a piece of logic that performs a specific, stateless action. If you find yourself writing the same block of code multiple times, it's a clear candidate for a function. Data goes in, a result comes out, and the function doesn't need to remember anything between calls.
Example: A function to calculate a specific evaluation metric.
- Create an object when you need to model a concept that has both data (state) and associated behaviors (methods). An object is ideal when you need to maintain state across multiple operations.
Example: A Model object that stores its weights (state) and provides train() and predict() methods (behaviors). The train() method modifies the model's internal state (the weights), which is then used by the predict() method.
How should you organize functions and objects in a project?
As a project grows, organizing code into logical modules (i.e., separate .py files) is essential for maintainability. The key principle is separation of concerns: each module should have a distinct and coherent purpose.
A typical MLOps project structure might include:
data.py: Contains functions and classes for data loading, validation, and preprocessing.models.py: Defines the architecture of your machine learning models, often as classes.train.py: Includes functions and classes responsible for the model training and evaluation loop.utils.py: A home for general-purpose helper functions used across the project.
This modular structure makes the codebase easier to navigate, test, and extend.
What are the trade-offs between these paradigms?
Choosing a paradigm involves trade-offs between simplicity, scalability, and performance.
| Paradigm | Pros | Cons | Best For |
|---|---|---|---|
| Procedural | Simple to learn, direct, and quick for small scripts. | Hard to maintain, test, and scale. Prone to bugs in complex systems. | Quick experiments, initial data analysis, and simple automation scripts. |
| Functional | Highly testable, predictable, and excellent for parallel processing. | Can have a steeper learning curve. Managing state can feel unnatural. | Data transformation pipelines, complex calculations, and concurrent workflows. |
| Object-Oriented | Excellent for managing complexity, highly reusable, and intuitive for modeling real-world systems. | Can lead to overly complex designs if not managed well. Can be more verbose than other paradigms. | Building large-scale, maintainable, and extensible MLOps applications. |
| Declarative | Simplifies complex tasks, reduces boilerplate code, and separates intent from implementation. | Less flexible than imperative code. Debugging can be difficult as it depends on the underlying framework. | Infrastructure as Code (IaC), model configuration, and query languages (e.g., SQL). |
Which paradigm is best for MLOps projects?
For building scalable and robust MLOps applications in Python, Object-Oriented Programming (OOP) is the recommended primary paradigm.
Python was designed with OOP at its core, and its strengths in this area are evident in major libraries like Pandas, scikit-learn, and Keras. OOP provides the encapsulation and abstraction needed to manage the complexity of production systems.
While Python supports functional programming (FP) concepts, it is not a pure functional language. It lacks key optimizations and features (e.g., tail-call optimization, true immutability) that languages like Haskell or Clojure provide.
Therefore, the most effective approach is to build an object-oriented foundation and strategically incorporate functional programming principles where they add the most value—such as in data processing pipelines. This hybrid approach leverages the best of both worlds.
What is the hybrid OOP and functional style?
A hybrid style strategically combines OOP's structure with FP's discipline to create clean, robust, and maintainable code. It involves using objects as the primary architectural component but applying functional principles to their design.
Key principles of the hybrid style include:
- Prefer Immutable Objects: Design classes where an object's state is set at creation and does not change. This reduces side effects and makes behavior easier to reason about.
- Write Pure Methods: Create methods that don't modify the object's state. Instead of changing internal attributes, they should return a new object or value.
- Isolate Side Effects: Confine operations that interact with the outside world (like logging, saving files, or database calls) to specific methods or classes. This separates pure, predictable logic from impure, state-changing actions.
- Use Functions for Stateless Operations: For any logic that is purely computational and doesn't need to be tied to an object's state, use standalone functions.
This approach gives you the architectural benefits of OOP (modeling complex systems) and the reliability of FP (predictability, testability), resulting in a highly effective MLOps codebase.
What are the best practices for writing functions and objects?
Adhering to best practices is crucial for creating code that is reliable, maintainable, and easy for others to understand.
- Single Responsibility Principle: Each function or class should do one thing and do it well. This makes them easier to understand, test, and reuse.
- Use Descriptive Names: Choose clear, unambiguous names for variables, functions, and classes that reveal their intent.
- Add Type Hints: Use type hints to declare the expected types for arguments and return values. This improves code clarity and allows for static analysis.
- Write Clear Docstrings: Document what your function or class does, its parameters, and what it returns, following the PEP 257 convention.
- Keep Functions Small: Limit the number of parameters and the lines of code in a function. Smaller functions are easier to read and test.
- Avoid Side Effects: Whenever possible, functions should not modify global variables or their input arguments. Instead, they should return new values.
- Handle Errors Gracefully: Anticipate potential errors (e.g., file not found, invalid input) and use try-except blocks to manage them.
- Write Unit Tests: Every function and method should have corresponding unit tests to verify its correctness and prevent regressions.