5.0. Design Patterns
What is a software design pattern?
A software design pattern is a reusable, well-tested solution to a common problem within a given context in software design. Think of it as a blueprint or a template for solving a specific kind of problem, not a finished piece of code. By using established patterns, you can build on the collective experience of other developers to create more efficient, maintainable, and robust applications.
Why are design patterns essential for MLOps?
In AI/ML engineering, you constantly face challenges related to complexity, change, and scale. Design patterns provide a structured way to manage these challenges.
- Enhance Flexibility: The AI/ML landscape is always evolving. A new model, data source, or framework might become available tomorrow. Patterns like the Strategy pattern allow you to design systems where components can be swapped out easily without rewriting the entire application.
- Improve Code Quality: Python's dynamic nature offers great flexibility, but it requires discipline to write stable and reliable code. Design patterns enforce structure and best practices, leading to a higher-quality codebase that is easier to debug and maintain.
- Boost Productivity: Instead of reinventing the wheel for common problems like object creation or component integration, you can use a proven pattern. This accelerates development, allowing you to focus on the unique, value-driving aspects of your project.
What are the most important design patterns in MLOps?
Design patterns are typically categorized into three types. For MLOps, a few patterns from each category are particularly vital.
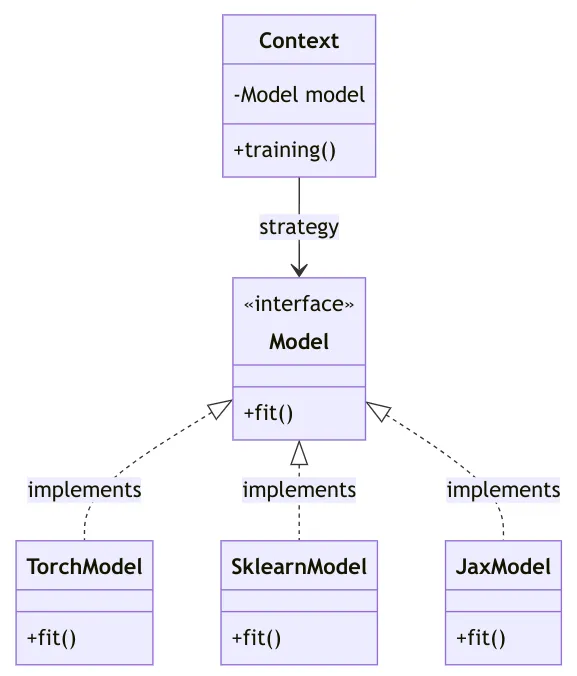
Strategy Pattern (Behavioral)
The Strategy pattern is fundamental for MLOps. It enables you to define a family of algorithms, encapsulate each one, and make them interchangeable. This decouples what you want to do (e.g., train a model) from how you do it (e.g., using TensorFlow, PyTorch, or XGBoost). This pattern adheres to the Open/Closed Principle, allowing you to add new strategies (like a new modeling framework) without modifying the client code that uses them.
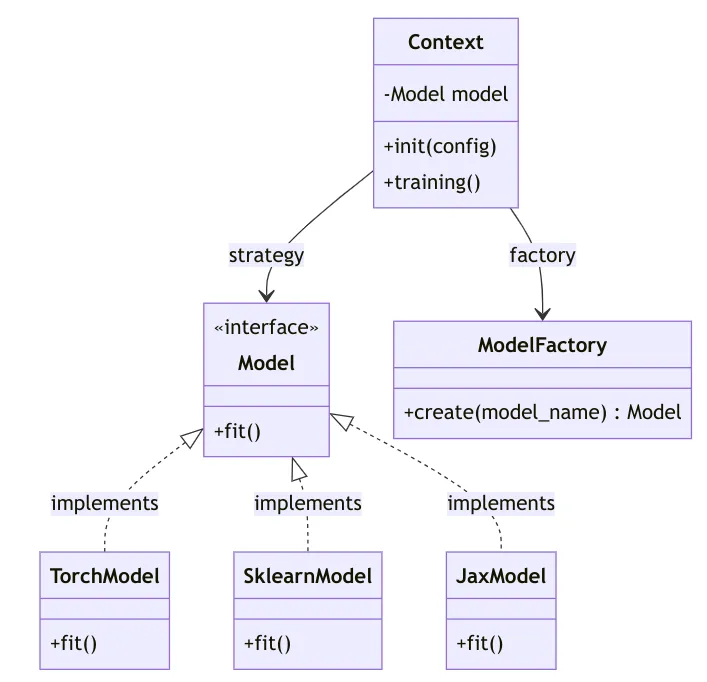
Factory Pattern (Creational)
The Factory pattern provides a way to create objects without exposing the creation logic to the client. In MLOps, this is incredibly useful for building pipelines that can be configured externally. For example, a factory can read a configuration file (e.g., a YAML file) to determine which type of model, data preprocessor, or evaluation component to instantiate at runtime. This makes your pipelines dynamic and configurable without requiring code changes.
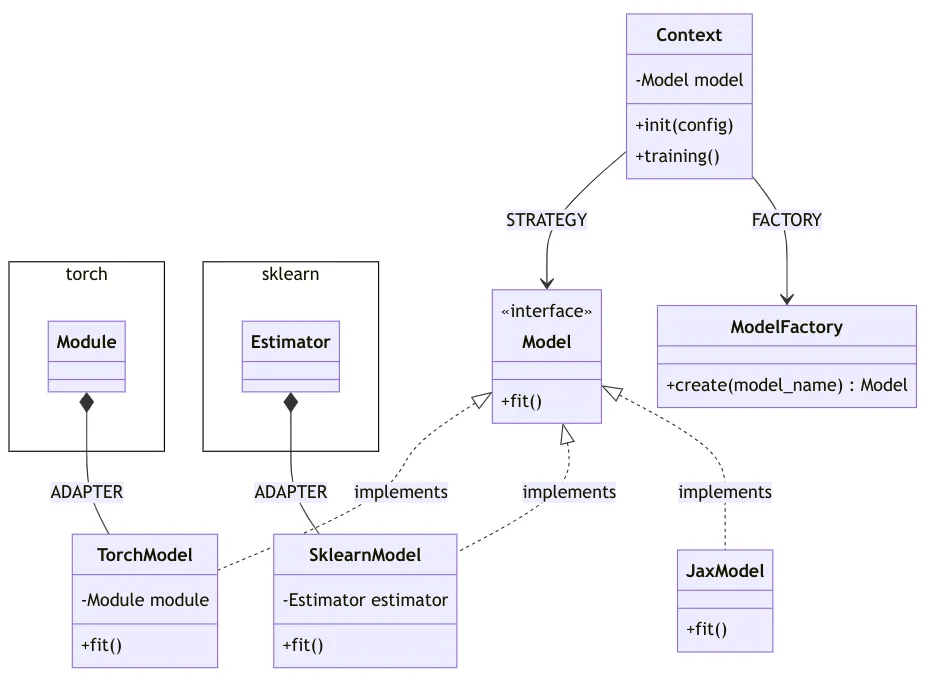
Adapter Pattern (Structural)
The Adapter pattern acts as a bridge between two incompatible interfaces. The MLOps ecosystem is filled with diverse tools and platforms, each with its own API. An adapter can wrap an existing class with a new interface, allowing it to work with other components seamlessly. For instance, you could use an adapter to make a model trained in Databricks compatible with a serving system running on Kubernetes, ensuring smooth integration between different parts of your stack.
How can you define software interfaces in Python?
In Python, an interface defines a contract for what methods a class should implement. This is key to patterns like Strategy, where different implementations must conform to a single API. Python offers two main ways to define interfaces: Abstract Base Classes (ABC) and Protocols.
Abstract Base Classes (ABCs) use Nominal Typing, where a class must explicitly inherit from the ABC to be considered a subtype. This creates a clear, formal relationship.
from abc import ABC, abstractmethod
import pandas as pd
class Model(ABC):
@abstractmethod
def fit(self, X: pd.DataFrame, y: pd.DataFrame) -> None:
pass
@abstractmethod
def predict(self, X: pd.DataFrame) -> pd.DataFrame:
pass
class RandomForestModel(Model):
def fit(self, X: pd.DataFrame, y: pd.DataFrame) -> None:
print("Fitting RandomForestModel...")
def predict(self, X: pd.DataFrame) -> pd.DataFrame:
print("Predicting with RandomForestModel...")
return pd.DataFrame()
class SVMModel(Model):
def fit(self, X: pd.DataFrame, y: pd.DataFrame) -> None:
print("Fitting SVMModel...")
def predict(self, X: pd.DataFrame) -> pd.DataFrame:
print("Predicting with SVMModel...")
return pd.DataFrame()
Protocols use Structural Typing, which aligns with Python's "duck typing" philosophy. A class conforms to a protocol if it has the right methods and signatures, regardless of its inheritance.
from typing import Protocol, runtime_checkable
import pandas as pd
@runtime_checkable
class Model(Protocol):
def fit(self, X: pd.DataFrame, y: pd.DataFrame) -> None:
...
def predict(self, X: pd.DataFrame) -> pd.DataFrame:
...
class RandomForestModel:
def fit(self, X: pd.DataFrame, y: pd.DataFrame) -> None:
print("Fitting RandomForestModel...")
def predict(self, X: pd.DataFrame) -> pd.DataFrame:
print("Predicting with RandomForestModel...")
return pd.DataFrame()
# This works because SVMModel has the required 'fit' and 'predict' methods.
class SVMModel:
def fit(self, X: pd.DataFrame, y: pd.DataFrame) -> None:
print("Fitting SVMModel...")
def predict(self, X: pd.DataFrame) -> pd.DataFrame:
print("Predicting with SVMModel...")
return pd.DataFrame()
| Feature | Abstract Base Classes (ABCs) | Protocols |
|---|---|---|
| Typing | Nominal ("is-a" relationship) | Structural ("has-a" behavior) |
| Inheritance | Required | Not required |
| Relationship | Explicit and clear hierarchy | Implicit, based on structure |
| Best For | Applications where you control the class hierarchy. | Libraries where you want to support classes you don't own. |
How can you simplify object validation and creation?
Pydantic is an essential library for modern Python development that uses type annotations for data validation and settings management. It is especially powerful in MLOps for ensuring data integrity and simplifying the implementation of creational patterns.
Validating Objects with Pydantic
Pydantic models validate data on initialization. This ensures that any configuration or data object meets your requirements before it's used in a pipeline, preventing runtime errors.
from typing import Optional
from pydantic import BaseModel, Field
class RandomForestConfig(BaseModel):
n_estimators: int = Field(default=100, description="Number of trees in the forest.", gt=0)
max_depth: Optional[int] = Field(default=None, description="Maximum depth of the tree.", gt=0)
random_state: Optional[int] = Field(default=42, description="Controls randomness.")
# Pydantic automatically validates the data upon instantiation.
# This would raise a validation error: RandomForestConfig(n_estimators=-10)
config = RandomForestConfig(n_estimators=150, max_depth=10)
print(config.model_dump_json(indent=2))
Streamlining Object Creation with Discriminated Unions
Pydantic's Discriminated Unions provide a powerful and concise way to implement a factory-like behavior. You can define a union of different Pydantic models and select the correct one at runtime based on a "discriminator" field (like KIND). This is often cleaner than a traditional Factory pattern.
from typing import Literal, Union
from pydantic import BaseModel, Field
class Model(BaseModel):
KIND: str
class RandomForestModel(Model):
KIND: Literal["RandomForest"]
n_estimators: int = 100
max_depth: int = 5
random_state: int = 42
class SVMModel(Model):
KIND: Literal["SVM"]
C: float = 1.0
kernel: str = "rbf"
degree: int = 3
# Define a Union of model configurations
ModelKind = RandomForestModel | SVMModel
class Job(BaseModel):
model: ModelKind = Field(..., discriminator="KIND")
# Initialize a job from configuration
config = {
"model": {
"KIND": "RandomForest",
"n_estimators": 100,
"max_depth": 5,
"random_state": 42,
}
}
job = Job.model_validate(config)
Additional Resources
- Design pattern examples from the MLOps Python Package
- Stop Building Rigid AI/ML Pipelines: Embrace Reusable Components for Flexible MLOps
- We need POSIX for MLOps
- Become the maestro of your MLOps abstractions
- Make your MLOps code base SOLID with Pydantic and Python’s ABC
- Design Patterns in Machine Learning Code and Systems
- Python Protocols: Leveraging Structural Subtyping